RMPE: Regional Multi-person Pose Estimation
RMPE: Regional Multi-person Pose Estimation 라는 논문에 대해 간략히 학습하였고 이를 바탕으로 내용을 정리해보도록 하자.
해당 논문은 AlphaPose 라고 github 에도 공개되어 있는 open source framework 에 대한 설명이다.
여러 명의 사람(Multi-person)에 대해 자세 추정을 하는 데 있어서 높은 성능을 보여준다.
Abstract

해당 논문에서는 Regional Multi-person Pose Estimation(RMPE) 라는 새로운 model 에 대해 제시한다.
이 RMPE 는 다음의 세 가지로 구성이 된다.
- Symmetric Spatial Transformer Network(SSTN)
- Parallel Pose Non-Maximum-Suppression(NMS)
- Pose-Guided Proposals Generator(PGPG)
이러한 새로운 모델을 통해 76.7mAP 라는 성능을 MPII(multi-person) dataset 에서 달성할 수 있었다.
또한 public 으로 공개되어있다.
Introduction

이 논문에서 제시하는 RMPE 모델을 비롯해 모든 Top-down(이 논문에서는 two-step) 방식의 multi-person pose estimator 에게는 human detector 로부터 발생할 수 밖에 없는 에러가 존재한다.
state-of-the-art 의 human detector 들조차 localization 과 recognition 분야에서 small error 가 발생하고 있는데(100%의 성능을 가진 detector 는 아직 없음) 이러한 small error 는 Single-Person Pose Estimator(SPPE) 에게는 많은 영향을 주기 때문이다.
이는 보통 bounding box 가 완전히 정확하지 않은 것에서부터 오게 된다.
따라서 이 논문에서는 이러한 inaccurate bounding box 에서도 제대로 pose 를 추정할 수 있도록 하는 것에 중점을 두었다.

RMPE 는 앞서 언급했듯이 SSTN, Parametric Pose NMS, PGPG 로 구성이 된다.
뒤에서 자세히 살펴볼테지만 간략하게 훑고 넘어가면 다음과 같다.
- Symmetric Spatial Transformer Network(SSTN)
- SPPE 의 양쪽에 붙어서 inaccurate bounding box 에서도 high-quality information 을 추출할 수 있게 한다.
- Parallel SPPE 를 branch 로 하나 더 가지고 있는데 이는 training 시 network 를 좀 더 optimal 하게 도와주는 부분이다.
- Parametric Pose NMS
- NMS 의 속성을 이용해 redundant pose 를 제거한다.
- 이 때 새로운 metric 인 pose similarity 를 사용하고, 이는 pose distance 를 기반으로 한다.
- Pose-Guided human Proposal Generator(PGPG)
- 해당 모듈은 training sample 을 augment 하고자 제시되었다.
- output 의 distribution 을 학습해 dataset 의 분포를 유지하며 적절한 training data 를 만들어내게 된다.
Related Work

이와 관련하여 기존의 연구들은 크게 두 가지 부류로 나뉜다.
- Single Person Pose Estimation
한 명에 대해 pose 를 추정하는 방식이다.- 전통적인 방법으로 pictorial structure, graph based 등이 있다.
- 최신의 기법인 deep learning 을 이용하는 방법들도 있는데, DeepPose, DNN based, CNN based 등의 여러 모델들이 있다.
- Multi Person Pose Estiamtion
여러 명의 사람의 자세를 동시에 추정하는 방법이다.
- Part based framework 로 keypoint 들을 바로 찾아내는 방법이 있다.
- two-step framework 는 먼저 사람의 bounding box 를 찾고 거기서 keypoint 를 찾아내는 방식이다.
Regional Multi-person Pose Estimation
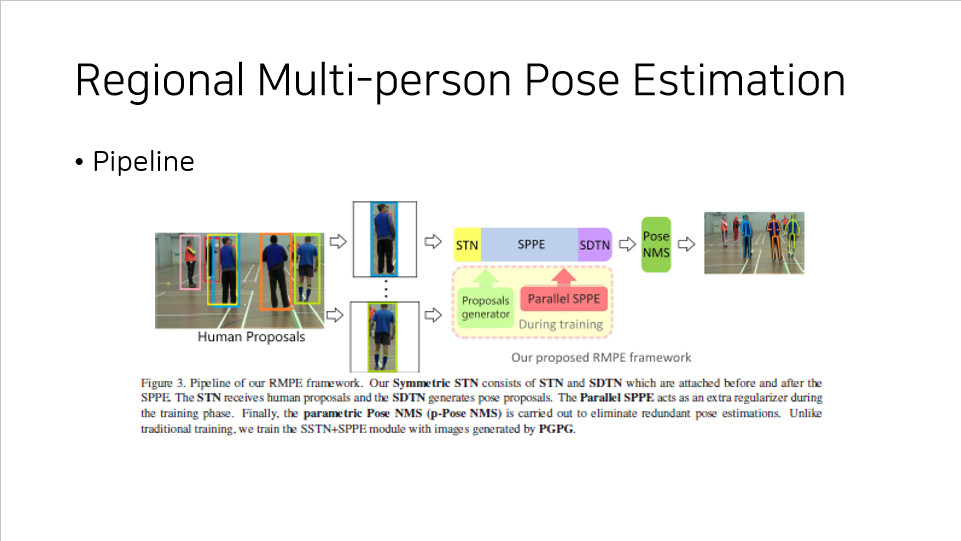
RMPE 의 구조는 대략적으로 위와 같다.
여기서 이들이 제시하는 Symmetric STN 이 왜 symmetric 인지 확인할 수 있다.
SPPE 를 통과시키기 전에 STN 을 붙여놓았고, 통과시킨 후 STN 과 비슷한 SDTN(Spatial De-Transformer Network) 을 붙여 놓았다.
또한 training phase 에서 Parallel SPPE 가 network 가 더 좋아질 수 있도록 도움을 주는 구조 역시 볼 수 있으며, PGPG 가 pose 를 generation 하여 보강된 data 로 더 학습을 하는 것도 표현되어 있다.
뒷부분에는 Parametric Pose NMS 가 중복되는 부분을 제거하여 최종적인 output 이 나타나는 것을 확인하고 넘어가자.
Symmetric STN and Parallel SPPE

Spatial Transformer Network 는 2D affine transformation 을 통해 high-quality dominant human proposal 을 추출하게 된다.
그리고 그 역과정은 Spatial De-Transformer Network(SDTN) 은 STN 을 통과한 결과값의 keypoint 들을 원래 image 에 대응되도록 remapping 해주는 과정을 나타낸다.
수식은 위의 슬라이드에서 확인할 수 있다.

SDTN 은 STN 의 역과정으로 볼 수 있고 위와 같이 $\gamma$ 를 $\theta$ 로부터 계산해 낼 수 있다.
이러한 방식에서의 이점은 위와 같이 back propagation 단계에서 gradient 값을 계산하기에도 쉽다.
$\theta_3$ 에 대한 gradient 는 다음과 같이 계산할 수 있다.
\[{\partial J(W,b) \over \partial\theta_3} = {\partial J(W,b) \over \partial\gamma_3} \times {\partial\gamma_3 \over \partial\theta_3}\]${\partial \left[ \gamma_1\ \gamma_2\right] \over \partial \left[ \theta_1\ \theta_2\right]}$ 와 ${\partial \gamma_3 \over \partial\theta_3}$ 는 위에 제시된 식에서 쉽게 구할 수 있다.

Parallel SPPE 는 bad result(local minimum) 를 피하기 위해 존재한다.
이 Parallel SPPE 는 원래의 SPPE 와 STN 을 공유하나 SDTN 은 존재하지 않는다.
여기서 나오는 output 은 center-located ground truth pose 와 직접적으로(directly) 비교된다.
이 branch 의 weights 는 고정되는데, 이렇게 고정을 시키고 STN module 에 center-located pose error 를 back propagation 하게 된다.
이 때, 현재 추정된 pose 가 중앙에서 멀다면 large error 가 전파되고, 이는 STN 이 학습을 잘하도록 하여 high-quality human dominant region 을 얻게 한다.
SSTN structure overview
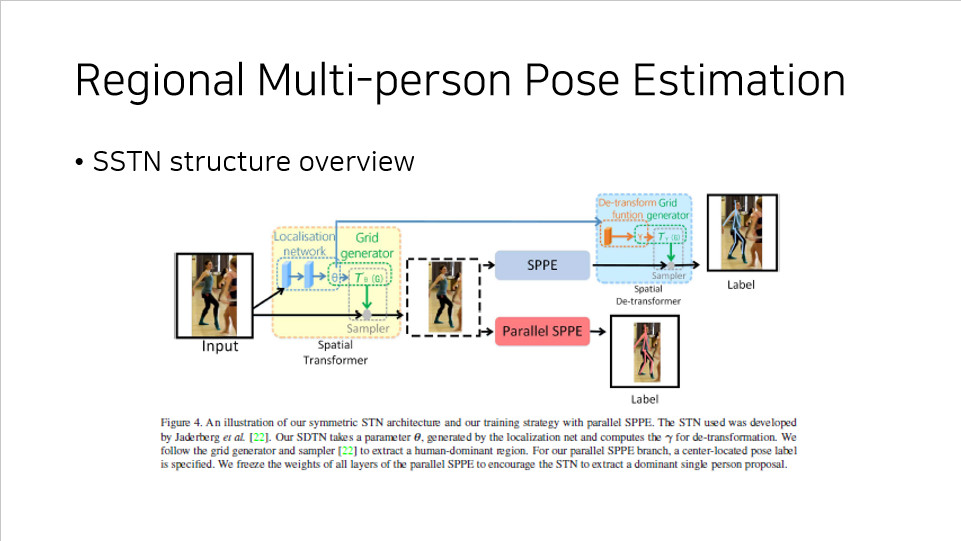
위에서 설명한 SSTN 의 구조는 위의 도식에서 확인할 수 있다.
Parametric Pose NMS

이들이 제시하는 두 번째 module 인 Parametric Pose NMS 는 기존의 pose NMS 를 개선시킨 것이라고 볼 수 있다.
NMS 의 scheme 을 이용해 redundant 를 줄이는 것을 목표로 하는데, 이 때 여기서 이 논문에서 제시하는 metric 은 pose similarity 라고 한다.
이 pose similarity 는 pose distance 와 spatial distance metric 을 같이 사용한다.
\[f(P_i, P_j|\Lambda,\eta) = \mathbb{1}[d(P_i, P_j|\Lambda, \lambda) \leq \eta]\]위의 수식을 해석하면 다음과 같다.
pose similarity $d$ 가 threshold $\eta$ 보다 작은 경우 redundant 이므로 NMS 로 삭제한다.
여기서 pose similarity $d$ 를 계산할 때 두 가지 metric 이 이용된다.
- pose distance
이는 pose 가 얼마나 다른지를 계산하는 수식이다. 가까울 수록 1의 값을 반환하며 멀 수록 그 값은 작아진다.
이 때, $\mathcal{B}$는 box center 를 나타내며 dimension 은 original box 의 1/10 이다. - spatial distance
이는 part 간의 거리에 대한 수식이다.
위의 두 metric 을 이용해 pose similarity 를 정의하게 되었다.

이 때, $f$ 는 4 개의 parameter 를 가지고 이를 exhaustive search 로 구하는 것은 overhead 가 큰 작업이다.
이 논문에서는 2 개의 parameter 를 먼저 구하고 그 다음 2 개의 paramter 를 계산하는 방식으로 효율적이게 구할 수 있었다.
Pose-Guided Proposals Generator

PGPG 를 생각해내게 된 배경은 다음과 같다.
학습을 시키는데에는 데이터가 많으면 좋다. 그런데 아무 데이터를 학습시킬 수는 없고 학습 시킬 수 있는 데이터가 필요한데, 원본 dataset 의 distribution 을 해치지 않으면서도 model 이 더 robust 하게 학습할 수 있는 방법이 없을까 해서 고안하게 되었다.
뿐만 아니라, human detector 가 bounding-box 를 친다고 했을 때 완벽하지 않은(imperfect) human proposal 이 만들어질 수도 있다. 이러한 것은 testing 때 모듈이 제대로 동작하지 않을 수도 있다.(앞서 이야기 한 것처럼)
주요한 insight 는 detected b-box 와 ground truth b-box 사이의 distribution 을 모델링 할 수 있게 하는 것이다.

| 따라서 그 분포인 $P(\delta B | P)$ 를 학습하면 좋으나 이를 직접적으로 학습하기에는 어렵다. |
그래서 이들은 $atom(P)$ 라는 atomic pose 를 학습하도록 설계했다.
이 atomic pose 는 pose 들의 사전(dictionary)이라고 볼 수 있다.
- 모든 pose 에 대해 torso(몸통) size 가 같도록 align 한다.
- 이를 k-means 를 통해 clustering 을 진행해주도록 한다.
- atomic pose 들에 대해 cluster center 를 계산한다.
- ground truth b-box 와 detected b-box 의 차이를 계산해준다. 이 때 각 person instance 들은 같은 atomic pose 를 공유한다.(같은 atomic pose 군이다)
- offset 이 frequency distribution 을 형성하게 된다.
| 이제 atomic pose $a$ 에 해당하는지 보고, $P(\delta B | a)$ 를 따르는 dense sampling 으로부터 추가적인 offset 을 생성해주게 된다. |
Experiments

이 논문에서는 MPII dataset 과 MSCOCO 2016 keypoints Challenge dataset 을 사용하였다.

first step 에서 사용할 human detector 로는 VGG-based SSD-512 를 선택하였다.
SPPE(Single-Person Pose Estimator) 는 stacket-Hourglass 를 이용하였으며 Parallel SPPE 역시 마찬가지이다. 이 때 stack 의 개수는 4이다.
STN 의 경우는 ResNet-18 을 사용하게 되었다.
여러 가지 실험을 통해 비교 우위의 성능을 내는 경우도 확인해보자.
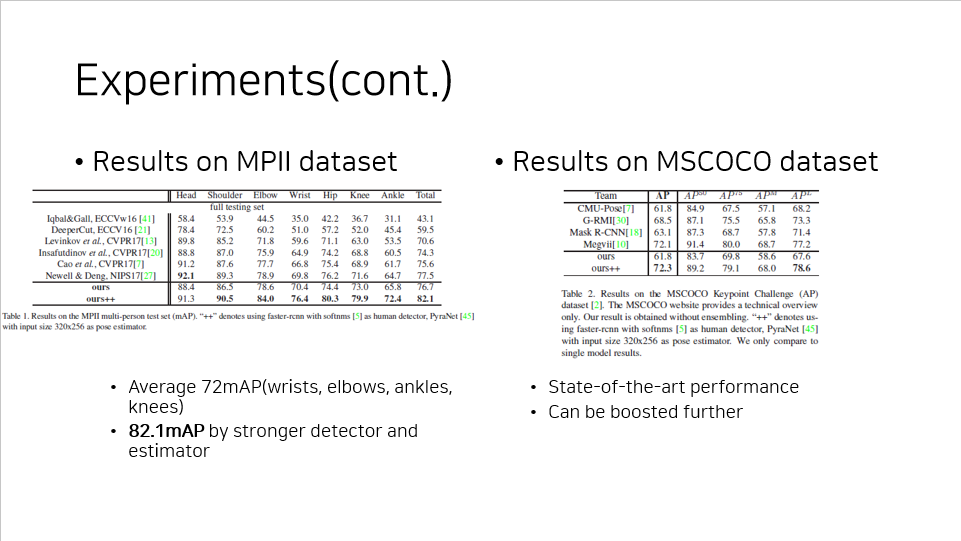
그 결과 준수하게 성능이 올라가는 것을 MPII dataset 에서 확인할 수 있었다.
특히 다른 모델들이 잘 추정하지 못하던 조금 특수한 부위(손목, 팔꿈치, 발목, 무릎 등)에 대한 성능은 평균적으로 72mAP 를 나타냈는데, 이는 다른 state-of-the-art 모델보다 3.3% 높은 수치이다.
강화된 버전으로는 82.1mAP 까지도 달성하는 것을 확인할 수 있었다.
그리고 MSCOCO dataset 에서도 78.6mAP 를 달성하는 것으로써 state-of-the-art perfomance 를 갱신할 수 있었고, 별 다른 튜닝을 하지 않았음에도 이러한 성능이 나온 것을 미루어보았을 때 더 나아갈 수 있으리라 판단된다.

잘 추정하는 것을 확인할 수 있다.

그러나 위와 같이 제대로 추정하지 못하는 케이스들이 존재했다.
- 드물게 취해지는 자세(사람 둘이서 시계?를 표현)
- 오른쪽 두 사람이 너무 많이 겹쳐져있음
- 중간의 노란 옷을 입은 사람이 human detector 로부터 검출되지 않음
- 아기들 위의 놀이 기구 같은 것이 사람처럼 생겼다고 판단되어서 추정해버림
이는 더 발전시켜서 보완해 볼 부분들이다.
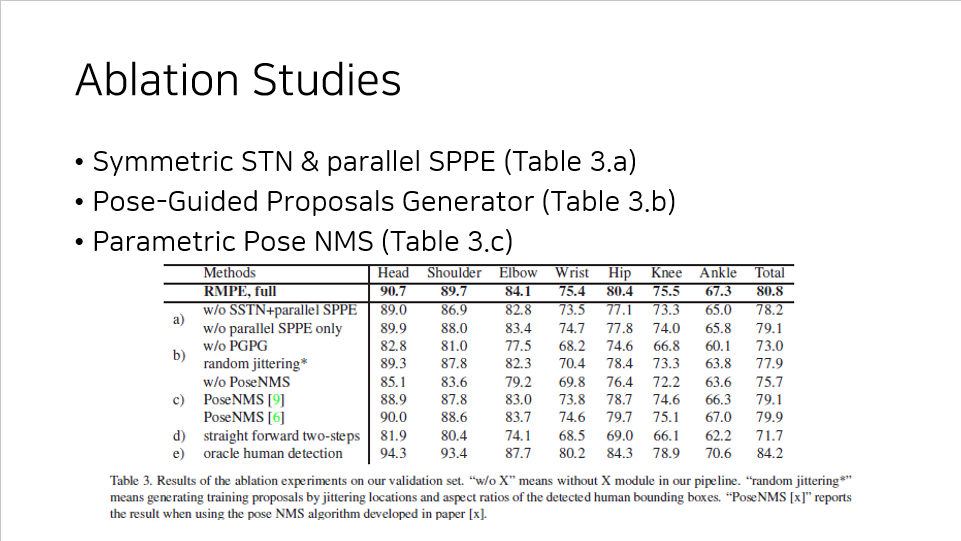
이 논문에서 제안한 세 가지 module 들이 정말 효용성 있는 것들인지 검증하는 실험도 진행해보았다.
각각의 module 들을 제거한 상태로 돌려보거나 바꾼 상태로 돌려봤을 때 위와 같은 결과를 얻을 수 있었다.
꽤 많이 점수가 내려가는 것을 확인할 수 있고, 따라서 이 논문에서 제시한 세 가지 module 은 효용성이 있다고 판단할 수 있다.
Conclusion

결론적으로 이 논문에서 제시하는 RMPE 는 높은 성능을 나타내며 state-of-the-art 를 갱신할 수 있었고, two-step framework 의 잠재적인 성능에 대해서 검증해 볼 수 있었다.
그리고 여기서 제시된 모델로 인해 SPPE(Single-Person Pose Estimator) 가 inaccurate bounding box 에서도 잘 검출할 수 있게 되기 시작했다.(localization error 를 극복할 수 있게 됨)
마지막으로 Parametric Pose NMS 역시 redundant 를 잘 제거해주는 것을 확인할 수 있었다고 한다.
Demo
AlphaPose

CrowdPose

PoseFlow

PoseFlow

이는 AlphaPose 의 github 에서 가지고 온 demo 영상이다.
굉장히 잘 추정하는 것을 확인할 수 있다.
밑의 두 가지는 PoseFlow 로 pose tracking 이 가능하게 구현해놓은 것이다.
이를 이용하면 post 의 context 를 이용해 순간적으로 가려지는 경우 등에도 대응할 수 있게 되는 것으로 보여진다.
Leave a comment