Cascade Feature Aggregation for Human Pose Estimation
Cascade Feature Aggregation for Human Pose Estimation
MPII Human Pose 데이터셋에서 두각을 나타내는 연구 결과인 Cascade Feature Aggregation for Human Pose Estimation 논문을 간략하게 정리해보자.
Abstract

이 논문에서 제안하는 CFA(Cascasde Feature Aggregation) 을 이용하여 MPII 에서 SOTA 를 갱신할 수 있었다.
high-level semantic information 의 이점을 활용하며, 여러 개의 Hourglass network 를 이용하였고, feature 와 result 를 복합적으로 사용한 것이 핵심이다.
Introduction
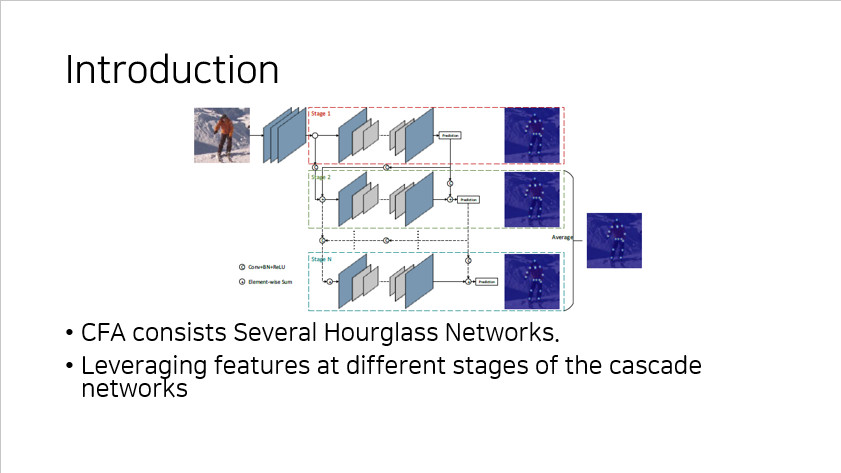
CFA 는 여러개의 Hourglass network 를 가지고 있다.
위의 도식에서 볼 수 있듯이 cascade 하게 모델을 구성하였으며, 이러한 방식을 활용해 각기 다른 stage 에서 feature 를 추출하여 가지고 가게 된다.

Related Work

Pose Estimation 분야는 크게 두 가지 접근법으로 나뉜다.
- Single-Stage Approach
- 기본 구조를 설계하는데 주로 관심을 많이 가진다.
- Hourglass : 다른 scale 에서의 정보에 대해 어떻게 처리할지에 대한 고찰이 있다.
- CPN(Cascaded Pyramid Network) : Hourglass 와 FPN(Parallel Feature Pyramid Network)의 이점을 모두 지닌다.
- Mutli-Stage Approach
- 다중 구조를 설계하는데 관심을 가진다.
- 기본 구조(e.g., Hourglass, ResNet, …)를 이용해 다양한 모델이 있다.
Network Architecture
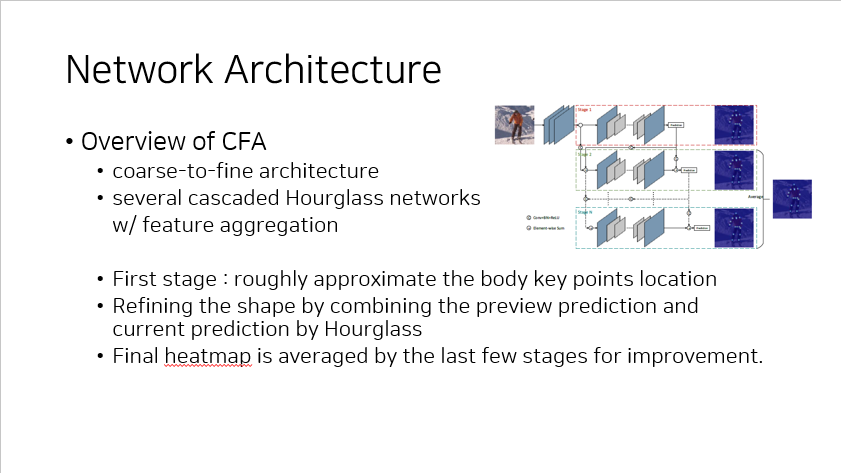
CFA 는 다른 많은 모델들처럼 coarse-to-fine 구조를 지닌다.
이 때, 여러 개의 Hourglass network 를 cascade 방식으로 연결시켰으며 이 연결에 있어서 feature 들을 aggregation 시켜 준다.
*element-wise sum
첫 번째 stage 는 keypoint 들의 위치를 대략적으로 추정하게 되고, 그 다음부터 Hourglass network 를 이용해 preview prediction 과 current prediction 을 결합하며 refining 하는 단계를 거친다.
최종적으로 마지막 몇 개의 stage(논문에서는 2~3개) 에서만 heatmap 을 추출해 최종적인 답을 내게 한다.
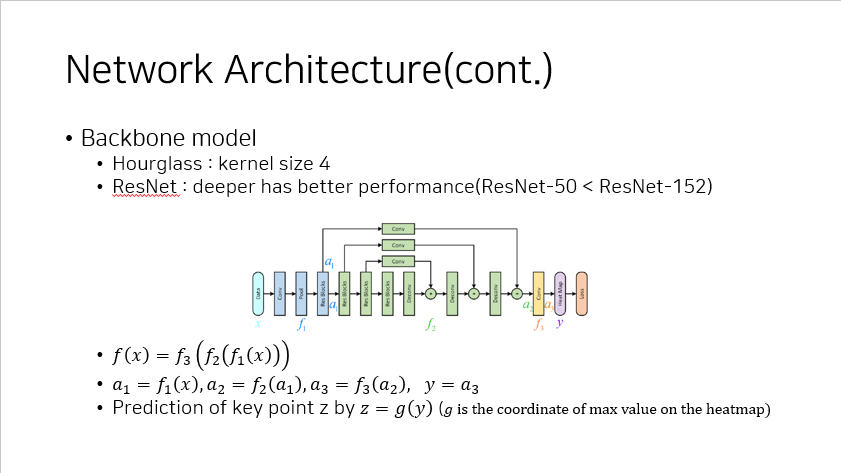
CFA 는 backbone model 로 kernel size 가 4 인 Hourglass 와 ResNet 을 이용하였다.
이 때, ResNet 의 경우 deep 할 수록 성능이 좋아지는 것을 실험적으로 확인할 수 있었는데, performance 와 computational cost 를 고려했을 때 ResNet-101 이 적절해보인다고 생각했다.
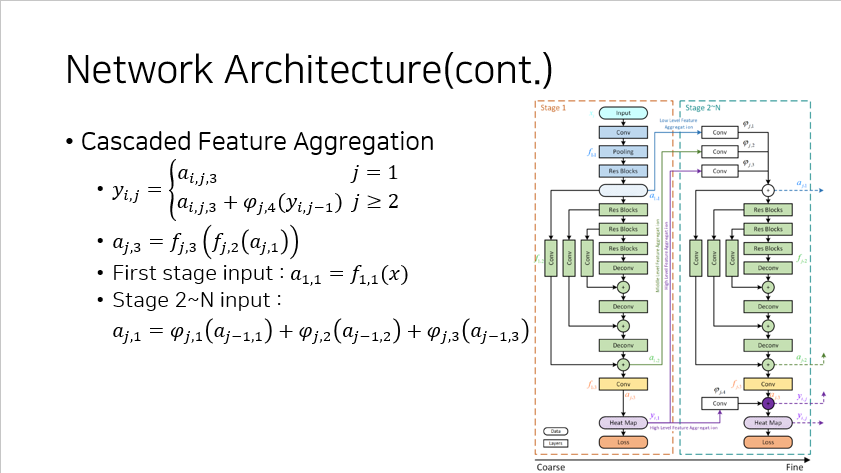
CFA 의 구조를 보면, low-level, middle-level, high-level 에서 각각 feature 들이 다음 stage 로 연결되는 구조를 확인할 수 있다.
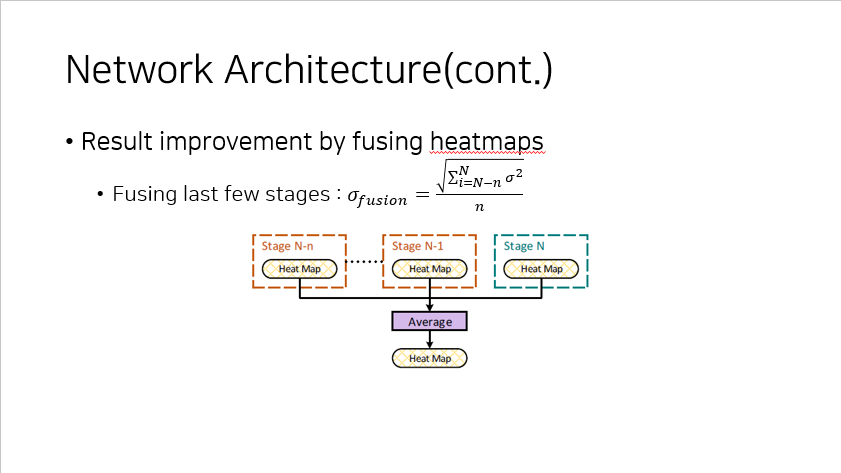
마지막 heatmap 을 위한 fusing 과정은 단순히 마지막 몇 개의 stage 들의 heatmap 의 평균이다.
Experiment

위와 같은 환경에서 실험을 진행하였다.

데이터셋으로는 MPII 와 LIP 를 사용하였고, 평가 지표(evaluation metric) 은 PCKh @ 0.5 이다.
그리고 성능을 조금 더 높이기 위해 double flipping test method 를 활용했는데, 이는 최종적으로 original image 와 flipped image 의 heatmap 의 평균을 사용하는 방식이다.

MPII 만을 이용했을 때와 MPII + HSSK(Human Skeletal System Keypoint) 를 이용했을 때를 비교해보면, MPII + HSSK 가 훨씬 더 좋은 성능을 내는 것을 확인할 수 있다.
훈련 시, ImageNet 에서 훈련된 모델로 첫 번째 stage 를 초기화하였으며 이후 stage 들은 random 하게 초기화해줬다.
이 때, 3 stage 보다 많은 stage 를 random 으로 초기화할 경우 수렴하게 만들기가 쉽지 않았다.
따라서 3 stage 를 먼저 훈련시킨 후 이를 이용해 그보다 더 많은 stage 를 훈련시키도록 해야한다.
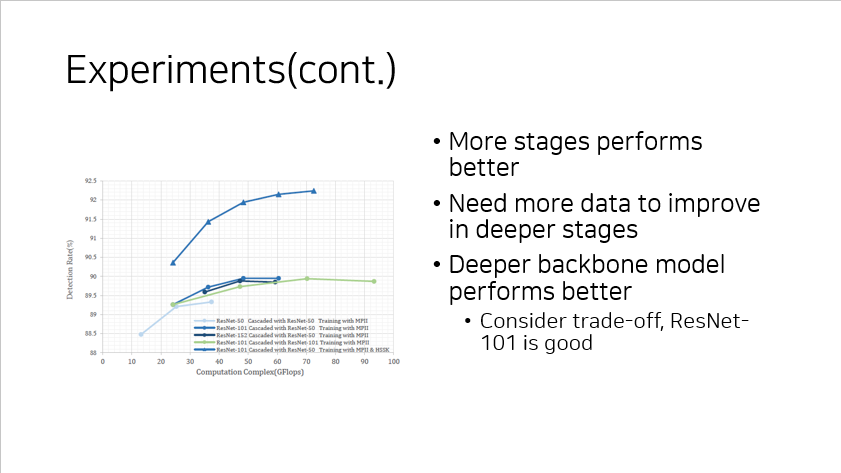
일정 stage(논문에서는 3 stage) 이후에는 어느 정도 성능이 수렴하는 것을 확인할 수 있다.
그런데 데이터셋을 보강하게 되면 stage 가 많아질 수록 성능이 더 올라가는 것을 확인할 수 있다.
뿐만 아니라, backbone model 인 ResNet 의 layer 가 깊어질 수록 성능이 더 좋아지는 것도 확인할 수 있었다.
그러나 trade-off 로써 적당한 것(ResNet-101)을 사용하는 것이 더 적절할 수 있다.
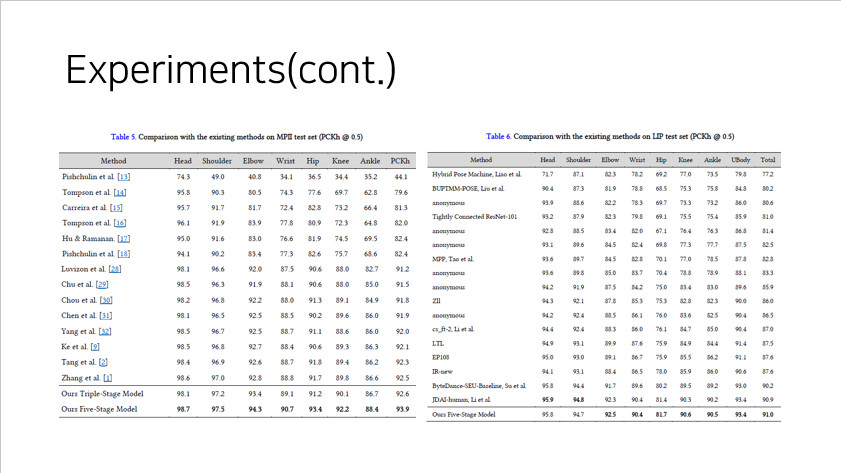
많은 모델들과 비교 실험을 했을 때 CFA 를 이용한 모델이 SOTA 의 성능을 내는 것을 확인할 수 있었다.
(좌 - MPII dataset / 우 - LIP dataset))

위의 이미지들은 stage 가 많아질 수록 결과값이 더 잘 나오는 것을 보여주며, 아래의 이미지들은 해당 모델이 제대로 결과를 내지 못한 것들에 대한 모습이다.
이는 illumination, occlusion, low resolution 등의 문제점으로 보이는데, 이를 해결하기 위해서는 데이터셋이 이러한 경우에 대해서 보강이 되어야함을 의미한다.
Conclusions

즉, 이번에 제시한 CFA 모델은 SOTA 의 성능을 보여줌을 확인할 수 있었다.
Cascaded Hourglass 와 low-level, middle-level, high-level 의 feature 들은 local detailed information 을 잘 나타내는 것으로 보여지고, global semantic information 역시 잘 작동하는 것으로 여겨진다.
성능 상의 효율성을 위해 적절히 backbone model 을 조정하는 것이 중요하며, 데이터셋이 더 보강되는 것이 아주 중요해보인다.
Leave a comment